Text-mined dataset of inorganic materials synthesis recipes
| Links: Link to Scientific Data
Semi-supervised machine-learning classification of materials synthesis procedures
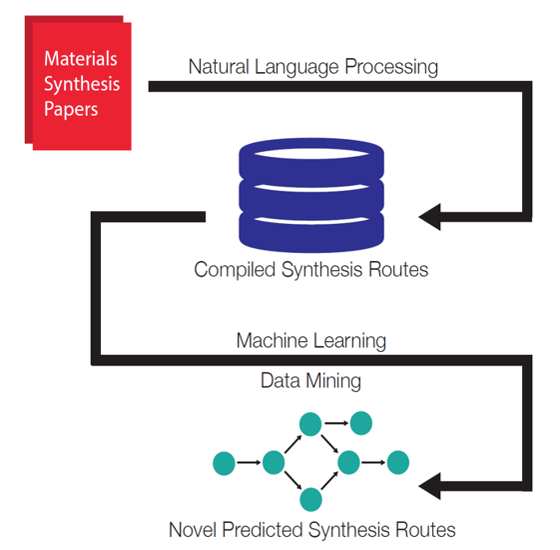
Digitizing large collections of scientific literature can enable new informatics approaches for scientific analysis and meta-analysis. However, most content in the scientific literature is locked-up in written natural language, which is difficult to parse into databases using explicitly hard-coded classification rules. In a series of papers, we have developed Natural Language Processing (NLP) algorithms to read the scientific literature and build text-mined databases of materials synthesis procedures. As there is no a fundamental theory for materials synthesis, one might attempt a data-driven approach for predicting inorganic materials synthesis, but this is impeded by the lack of a comprehensive database containing synthesis processes. To overcome this limitation, we have generated a dataset of “codified recipes” for solid-state synthesis automatically extracted from scientific publications. The dataset consists of 19,488 synthesis entries retrieved from 53,538 solid-state synthesis paragraphs by using text mining and natural language processing approaches. Every entry contains information about target material, starting compounds, operations used and their conditions, as well as the balanced chemical equation of the synthesis reaction. The dataset is publicly available and can be used for data mining of various aspects of inorganic materials synthesis.
Scientific Data – Text-mined dataset of inorganic materials synthesis recipes (2019)